
Redis入门
Redis之入门教程
关键词
Redis: Redis是一个开源(BSD许可)内存数据结构存储. 可用作数据库, 缓存和消息代理.NoSql: 泛指非关系型的数据库.Docker: 是一个开源的应用容器引擎. 可以非常方便地部署服务.缓存:高速缓存简称缓存,原始意义是指访问速度比一般随机存取存储器(RAM)快的一种RAM,通常它不像系统主存那样使用DRAM技术,而使用昂贵但较快速的SRAM技术. 简言之, 缓存是在计算机上的一个原始数据的复制集, 让数据更接近使用者, 有着更快的访问速度.
前言
本文阐述了Redis的简单使用, 包括使用Docker启动redis服务端、redis客户端的使用、redis常用数据结构及其使用方法和场景.
使用入门
服务端
本文使用Docker启动redis服务端.
Docker Hub: https://hub.docker.com/_/redis
docker container run \
--rm \
--name redis \
-p 6379:6379 \
-d \
redis:5.0--rm: 退出后删除--name: 指定容器名-p: 映射端口-d: 后台运行并输出容器ID
客户端
redis-cli
原生redis客户端
在宿主机上执行docker exec -it redis redis-cli即可进入容器内的redis客户端. 注: 命令中redis为前文中启动redis时指定的容器名: --name redis(也可用容器id替代).
root@ubuntu:/home/ubuntu/docker/redis$ docker exec -it redis redis-cli
127.0.0.1:6379> medis
medis是一个图形化redis客户端工具. 支持命令.
数据结构
Redis不是普通的键值对存储, 它实际上是一个支持不同类型数据结构的服务器. 这意味着Redis与传统的键值存储不同, 具有更多更复杂的数据结构, 下文将简要介绍Redis的数据结构及用法.
Binary-safe strings
应用场景:
- 缓存HTML片段或页面
- 缓存某个接口的返回值等.
Redis String类型是与Redis Key关联的最简单的值类型.
打开redis-cli执行简单的string操作. (后文中所有示例都将使用redis-cli)
127.0.0.1:6379> SET mykey myvalue
OK
127.0.0.1:6379> GET mykey
"myvalue"
127.0.0.1:6379> KEYS my*
1) "mykey"
127.0.0.1:6379> EXISTS mykey
(integer) 1
127.0.0.1:6379> DEL mykey
(integer) 1
127.0.0.1:6379> GET mykey
(nil)SET: 设置KEY对应的值.GET: 获取指定KEY的值.KEYS: 查询KEY.EXISTS: 查询KEY是否存在.DEL: 删除KEY.EXPIRE: 指定KEY的过期时间 (SET命令也可通过参数指定过期时间)
Lists
应用场景:
- 记录用户发布到社交网络的最近更新.
- 流程之间的通信, 借助redis列表实现
生产者 - 消费者模式.
根据插入顺序排序的字符串元素的集合. 其实现基于链表, 因此即使数据量极大的情况下, 也能在常量时间内添加元素到列表头或尾.
127.0.0.1:6379> RPUSH mylist a # 尾部增加元素a
(integer) 1
127.0.0.1:6379> RPUSH mylist b # 尾部增加元素b
(integer) 2
127.0.0.1:6379> LPUSH mylist first # 头部增加元素first
(integer) 3
127.0.0.1:6379> LRANGE mylist 0 -1 # 获取mylist全部元素
1) "first"
2) "a"
3) "b"
127.0.0.1:6379> LRANGE mylist 0 -2 # 获取mylist第一~倒数第二的全部元素
1) "first"
2) "a"
127.0.0.1:6379> RPOP mylist # 从尾部弹出一个元素
"b"
127.0.0.1:6379> LPOP mylist # 从头部弹出一个元素
"first"
127.0.0.1:6379> LRANGE mylist 0 -1
1) "a"
127.0.0.1:6379> RPUSH mylist b c d e f g # 尾部增加 b c d e f g 元素
(integer) 7
127.0.0.1:6379> LRANGE mylist 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
7) "g"
127.0.0.1:6379> LTRIM mylist 0 2 # 截取索引0~2的元素(其余元素丢弃)
OK
127.0.0.1:6379> LRANGE mylist 0 -1
1) "a"
2) "b"
3) "c"RPUSH: 在列表尾部(右侧)增加新元素.LPUSH: 在列表头部(左侧)增加新元素.LRANGE: 获取存储在列表中指定索引范围的值, 值得注意的是,start和stop从0开始, 支持负值, 负值的意义是从尾部开始偏移, 倒数第一个为-1, 倒数第二个为-2, 依此类推. 故命令LRANGE mylist 0 -1的含义为获取全部元素(第一个到最后一个).RPOP: POP相信很多人并不陌生, 弹出一个元素(获取并删除),RPOP的含义就是从尾部(右侧)弹出一个元素.LPOP: 与RPOP类似, 其含义为从列表头部(左侧)弹出一个元素.LTRIM: 截取元素, 指定截取的范围, 其余丢弃.
Sets
应用场景:
- 希望存储一个不重复的数据集合,
- 获取两个人的共同好友
Sets是字符串的无序集合. 使用过Java的读者应该对HashSet并不陌生, 其特点就是无序且元素不重复, Redis的Set也有这样的特点.
127.0.0.1:6379> SADD myset a # 将元素 a 存入 myset
(integer) 1
127.0.0.1:6379> SMEMBERS myset # 获取 myset 的元素
1) "a"
127.0.0.1:6379> SADD myset a # 再次将元素 a 存入 myset, set能保证元素唯一,故此次存入返回0
(integer) 0
127.0.0.1:6379> SMEMBERS myset
1) "a"
127.0.0.1:6379> SADD myset b c # 将元素 b、c 存入 myset
(integer) 2
127.0.0.1:6379> SMEMBERS myset
1) "b"
2) "c"
3) "a"
127.0.0.1:6379> SPOP myset # 随机弹出一个元素
"c"
127.0.0.1:6379> SMEMBERS myset
1) "b"
2) "a"
127.0.0.1:6379> SADD myset c # 将刚刚弹出的c放回去
(integer) 1
127.0.0.1:6379> SPOP myset # 再次随机弹出, 这一次弹出的是b
"b"
127.0.0.1:6379> SMEMBERS myset
1) "c"
2) "a"SADD: 向set添加元素.SMEMBERS: 获取set的元素.SPOP: 随机弹出一个元素.- Sets还可以进行交集、并集、差集计算等操作.
Sorted sets
应用场景:
- 以某个条件为权重进行排序, 例如排行榜.
有序集合是一种类似于混合了Set和Hash的数据结构, 由唯一的、 非重复的字符串元素组成. 因此在一定程度上也算是一种集合(Set).
有序集合中的每个元素都与浮点值相关联, 称为分数 (score) (这就是为什么说它也类似于散列(hash), 因为每个元素都映射到一个值).
127.0.0.1:6379> ZADD students 99 piaoruiqing # 向students存入piaoruiqing且指定其score为99
(integer) 1
127.0.0.1:6379> ZADD students 98 zhangsan
(integer) 1
127.0.0.1:6379> ZADD students 85 lisi
(integer) 1
127.0.0.1:6379> ZADD students 90 wangwu
(integer) 1
127.0.0.1:6379> ZRANGE students 0 -1 # 获取students全部元素
1) "lisi"
2) "wangwu"
3) "zhangsan"
4) "piaoruiqing"
127.0.0.1:6379> ZRANGE students 0 -1 WITHSCORES # 升序获取students全部元素及其score
1) "lisi"
2) "85"
3) "wangwu"
4) "90"
5) "zhangsan"
6) "98"
7) "piaoruiqing"
8) "99"
127.0.0.1:6379> ZREVRANGE students 0 -1 WITHSCORES # 降序获取students全部元素及其score
1) "piaoruiqing"
2) "99"
3) "zhangsan"
4) "98"
5) "wangwu"
6) "90"
7) "lisi"
8) "85"
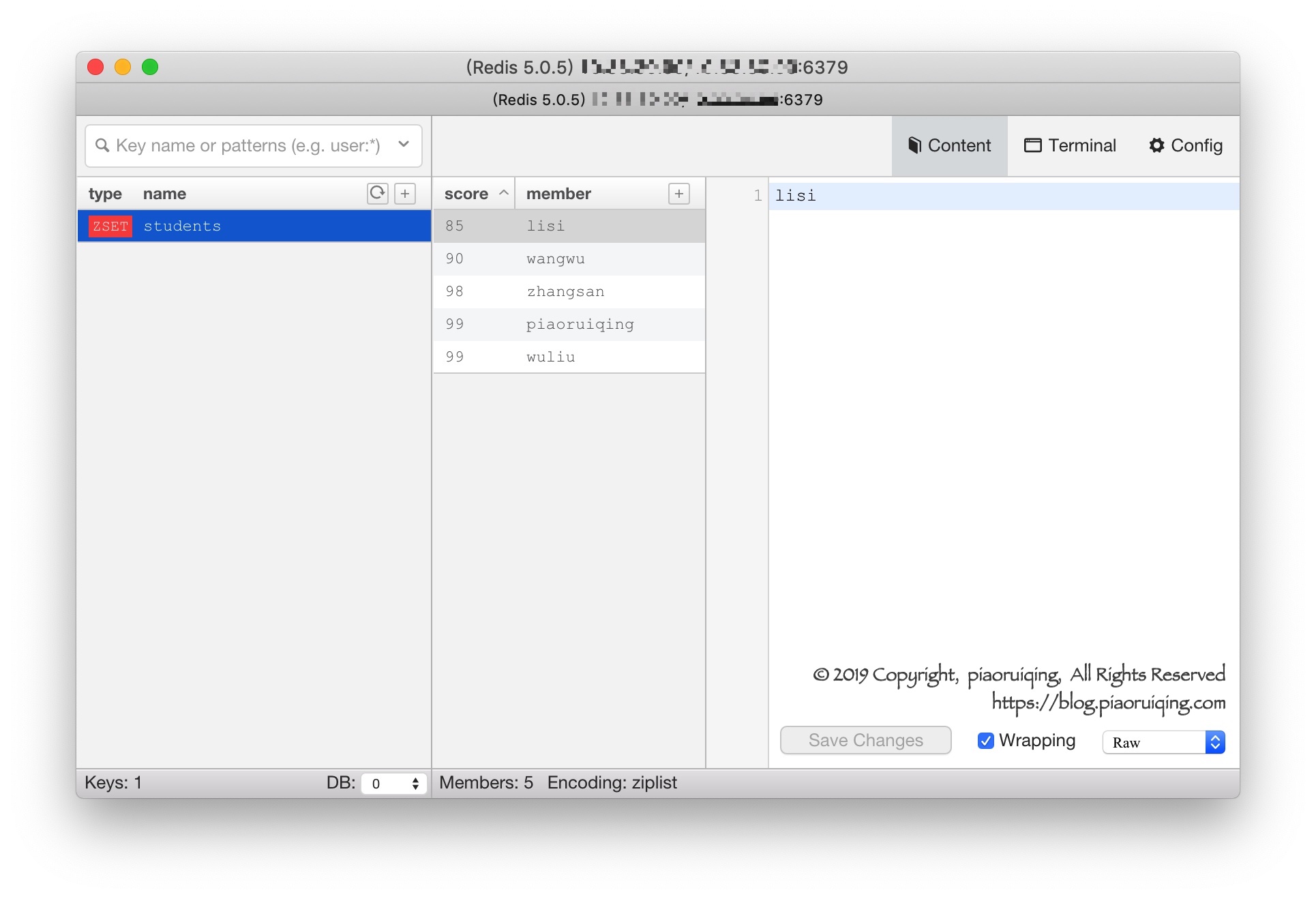
127.0.0.1:6379> ZADD students 99 wuliu # 不同元素评分可以相同(piaoruiqing和wuliu都是99)
(integer) 1
127.0.0.1:6379> ZREVRANGE students 0 -1 WITHSCORES
1) "wuliu"
2) "99"
3) "piaoruiqing"
4) "99"
5) "zhangsan"
6) "98"
7) "wangwu"
8) "90"
9) "lisi"
10) "85"为了更直观, 让我们从Medis查看下这条数据:
本文发布于朴瑞卿的博客, 允许非商业用途转载, 但转载必须保留原作者朴瑞卿 及链接:https://blog.piaoruiqing.com.
如有授权方面的协商或合作, 请联系邮箱: piaoruiqing@gmail.com.
Hashes
应用场景:
- 适合存储对象, 可用缓存用户信息等
Hashes是一个field-value的映射表, 适合存储对象.
127.0.0.1:6379> HSET user:9527 user_name piaoruiqing verified 1 user_level 99 # 存
(integer) 1
127.0.0.1:6379> HGET user:9527 user_name # 获取 user:9527 的user_name字段的值.
"piaoruiqing"
127.0.0.1:6379> HGET user:9527 user_level
"99"
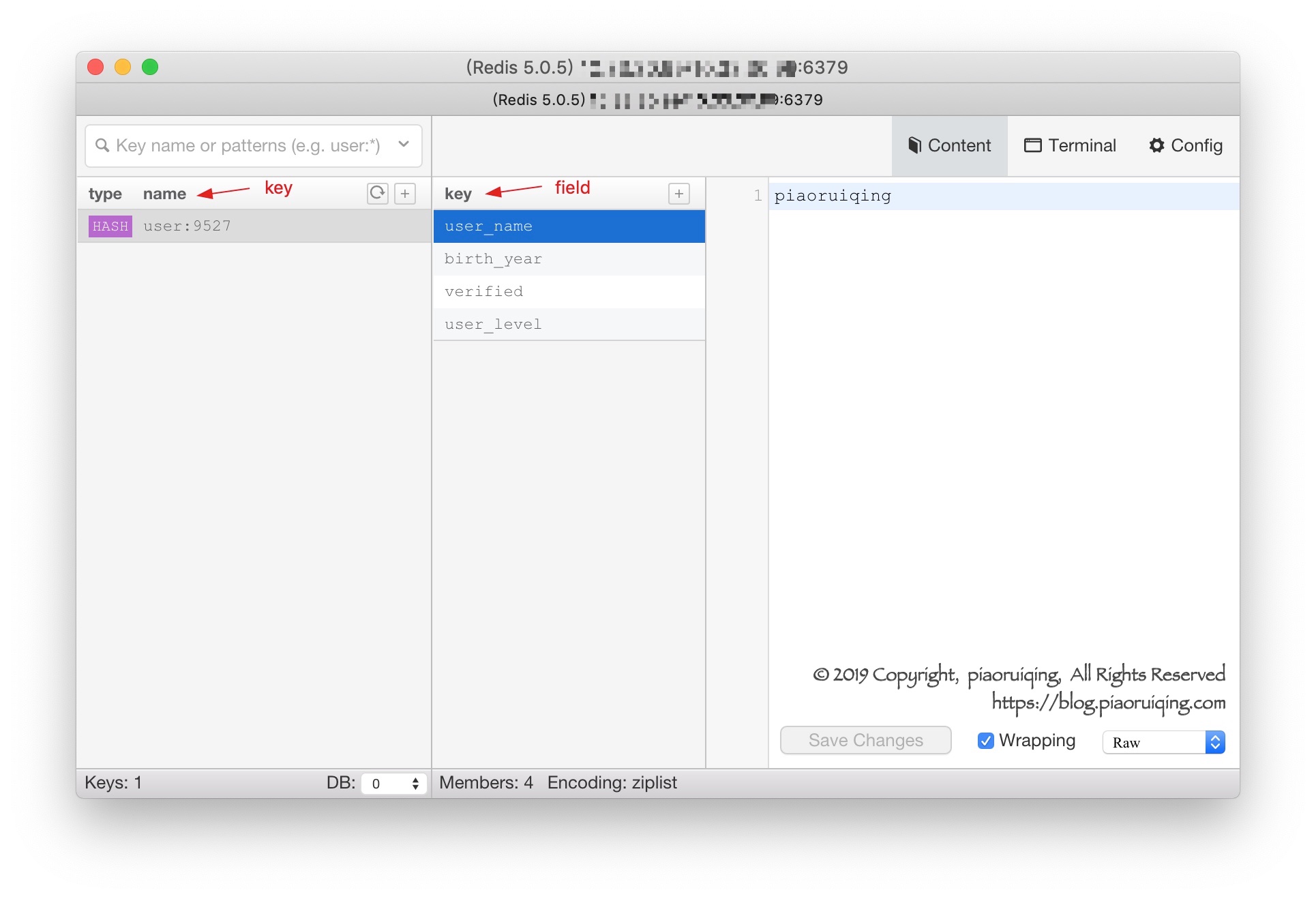
127.0.0.1:6379> HGETALL user:9527 # 获取 user:9527 的全部字段和元素
1) "user_name"
2) "piaoruiqing"
3) "birth_year"
4) "1977"
5) "verified"
6) "1"
7) "user_level"
8) "99"为了更直观, 让我们从Medis查看下这条数据:
值得注意的是: 图中第一栏标题的type是数据类型, name是redis的key, 第二列标题的key, 就是Hashes的field. 请读者切勿被界面中的文字误导.
-
HSET: 向hashs存入元素. -
HGET: 获取key某字段对应的元素. -
HGETALL: 获取key的全部字段和元素. -
:: 值得一提的是一般将冒号:作为redis key的分隔符. 冒号在早期的redis版本中是一个存储命名空间数据的概念, 是一个"遗留下来"的"约定", 冒号并不强制使用, 如果有需要, 你可以选择_、、、,等任何字符分割你的key, 但推荐使用:, 因为很多客户端都默认将其作为命名空间进行展示, 比如Redis Desktop Manager就使用冒号将redis的key分割为树状结构进行展示, 如图: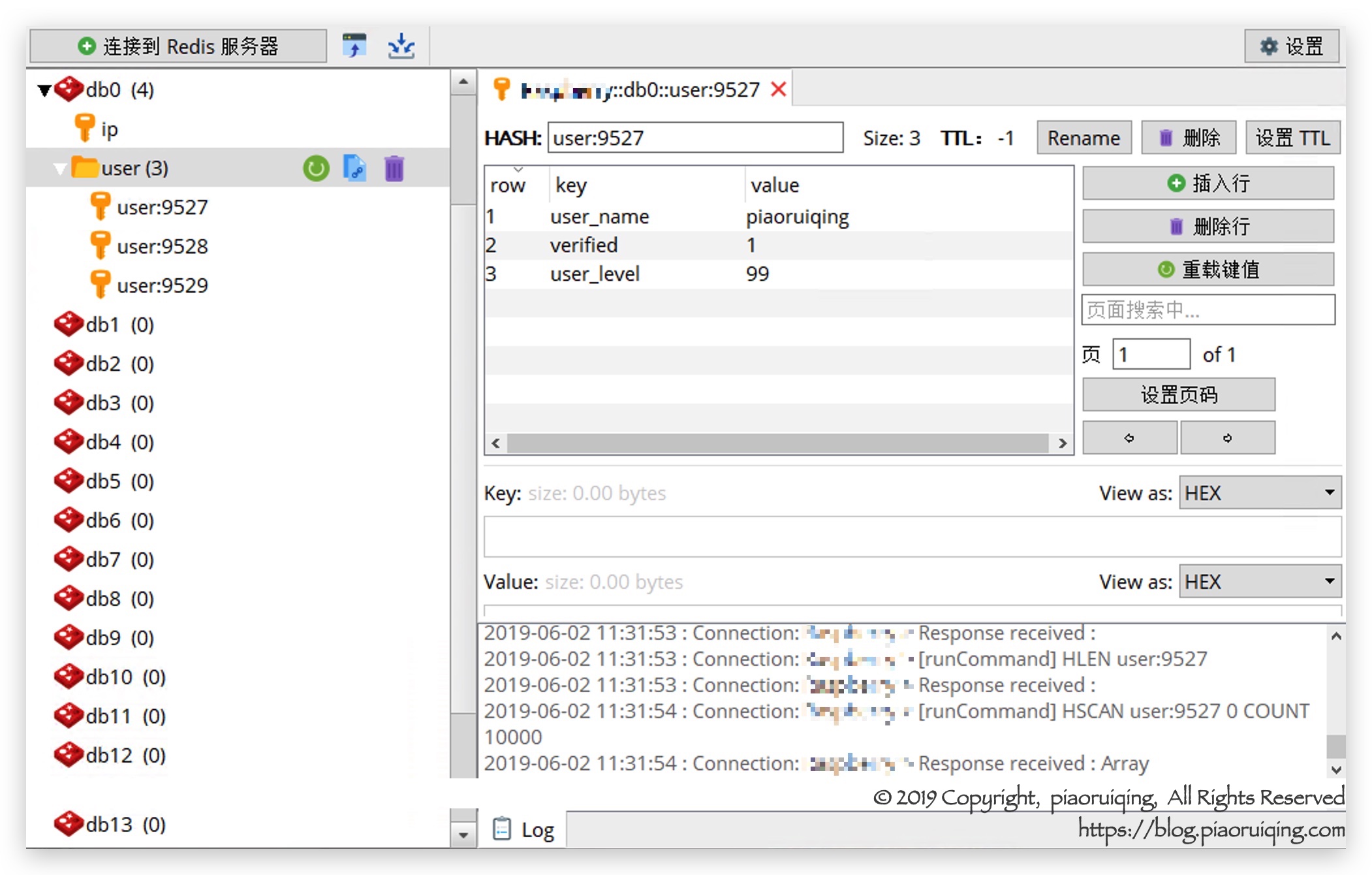
HyperLogLogs
应用场景:
- 统计网站访问IP总量.
HyperLogLogs是用来计算唯一事物出现概率的一种数据结构. 它并不存储元素本身, 仅仅根据元素来计算基数. 即使元素很大它也能占用极小的空间快速计算出基数.
127.0.0.1:6379> PFADD ip 192.168.0.1 192.168.0.2 192.168.0.3 192.168.0.2 # 存入四个IP元素
(integer) 1
127.0.0.1:6379> PFCOUNT ip # 获取当前IP总量 (192.168.0.2出现过两次, 故获取的值是3而不是4)
(integer) 3Streams
应用场景:
- 消息队列
Stream是Redis 5.0引入的一种新数据类型, 其设计借鉴了Kafka, 以完全不同的方式实现了与Kafka类似的思想: 允许一组客户端合作消费相同的消息流的不同部分. 弥补了Redis Pub/Sub不能持久化消息的缺陷
127.0.0.1:6379> XADD mystream * sensor_id 9527 temperature 19.9 # 存入
"1559476322048-0"
127.0.0.1:6379> XADD mystream * sensor_id 9528 temperature 19.9
"1559476326813-0"
127.0.0.1:6379> XRANGE mystream - + # 获取
1) 1) "1559476322048-0"
2) 1) "sensor_id"
2) "9527"
3) "temperature"
4) "19.9"
2) 1) "1559476326813-0"
2) 1) "sensor_id"
2) "9528"
3) "temperature"
4) "19.9"
127.0.0.1:6379> XRANGE mystream - + COUNT 1 # 获取(升序)
1) 1) "1559476322048-0"
2) 1) "sensor_id"
2) "9527"
3) "temperature"
4) "19.9"
127.0.0.1:6379> XREVRANGE mystream + - COUNT 1 # 获取(降序)
1) 1) "1559476326813-0"
2) 1) "sensor_id"
2) "9528"
3) "temperature"
4) "19.9"XADD: 存入, 命令XADD mystream * sensor_id 9527 temperature 19.9中*表示自动生成IDXRANGE: 获取(升序)XREVRANGE: 获取(降序)
结语
本文阐述了redis的简单使用方式及常用数据结构, 需要深入了解的读者可以访问redis官网获取更详细的文档.
后续文章将阐述redis在实际开发中的使用方式,如: Java客户端集成、Lua脚本的使用、实践案例等, 敬请关注.